Reflecting on a year of conversations - Chat GPT's impact and evolution
In the ever-evolving landscape of technological advancements, there arises, once in a generation, a ground-breaking innovation that serves as the cornerstone upon which sweeping transformations across diverse industries are built. Arguably, the dial-up modem which achieved widespread adoption during the mid 1990s, was a transformational technology that paved the way for many of us to access the World Wide Web. Some of us will recall the domestic dramas when the home phone line (there was normally one per household) was unavailable as it was being used to “connect to the internet”.
The whistles and buzzes from the modem as it created a connection between households and the internet gave rise to the dot com boom of the late 90s and early 00s, where households could now buy products and goods ‘on-line’. The growth of online access and activity led to the creation of new companies such as Amazon in 1995 and Google in 1998. With the launch of ChatGPT3.5 almost 12 months ago, and the significant adoption of Generative AI in both personal, educational and business usage, is Generative AI the next transformational technology? As we reflect back on the last 12 months, what have we learned, what are the challenges and where will this technology take us?
The technologies that support Generative AI, in particular the Transformer architecture (the ‘T’ in ChatGPT) has been around since 2017 when researchers from Google Brain and the University of Toronto published their seminal paper ‘Attention Is All You Need’. While there have been many implementations of the ‘Transformer’ architecture since its inception, it was the introduction of ChatGPT3.5, on the 30th November, 2022, that sparked the surge of interest and application of this technology.
The growth and sign-up of users to ChatGPT broke many online records. ChatGPT reached 100 million users in 2 months; it took TikTok 9 months to reach that number of users, YouTube 18 months and X (previously known as Twitter) 5 years. Yet, ChatGPT’s impact extended fair beyond its user-base; it ignited an avalanche of interest amongst the media, commentators and the public at large, casting a spotlight on the realm of Artificial Intelligence, its applications and risks. Indeed, due to this phenomenal increase in the awareness of Artificial Intelligence, ‘AI’ was declared the Collins Dictionary Word of the Year for 2023, underscoring the profound cultural impact of this technology in society.
ChatGPT, Google’s BERT and Meta’s Llama belong to the realm of Large Language Models (LLMs), a classification of the broader category of Foundation Models. These models are constructed using trillions of bytes of data, sourced from the internet, books, articles, and other written content, costing millions of dollars to develop. The extensive and diverse dataset on which Foundation Models are trained on, provide them with the flexibility on the tasks they can be applied too.
The type of data used to train a Foundation Model determine its ‘mode’. For instance, a Large Language Model (LLM) is a type of Foundation Model trained on text. Since the launch of ChatGPT3.5 in 2022, the majority of Foundation Models released have been Large Language Models. However, there are other models developed and available. OpenAI have recently released ChatGPT 4V(ision) - a Large Multi-modal Model (LMM). This model not only understands text but also incorporates visual understanding, making it more applicable to a wider range of tasks and applications.
There applications of Large Language Models are extensive, diverse and quite numerous. In financial services, Bloomberg has developed BloombergGPT, a Large Language Model trained on a wide range of both Bloomberg data and publicly available data. In the medical field, ClinicalGPT, was “explicitly designed and optimised for clinical scenarios. By incorporating extensive and diverse real-world data, such as medical records, domain- specific knowledge, and multi-round dialogue consultations in the training process, ClinicalGPT is better prepared to handle multiple clinical task”.
In software development, the partnership between Microsoft and OpenAI has resulted in Github Copilot. Research conducted on the use of this tool showed that “88% of developers reported maintaining flow state with GitHub Copilot Chat because they felt more focused, less frustrated, and enjoyed coding more”. Despite the success of these, and other, implementations of Large Language Models, what is common across all successful implementations is the necessity for human engagement – ‘Human in the Loop’.
Why is there a need for to ensure that we keep ‘Humans in the Loop’? What are the challenges with Large Language Models? Large Language Models provide answers in a confident and authoritative tone – yet they do not know what the truth is. They are built upon statistical models and, as noted in Time magazine, “Large language models don't inform users that they are making statistical guesses. They present incorrect guesses with the same confidence as they present facts. Whatever you ask, they will come up with a convincing response, and it is never “I don’t know,” even though it should be.”
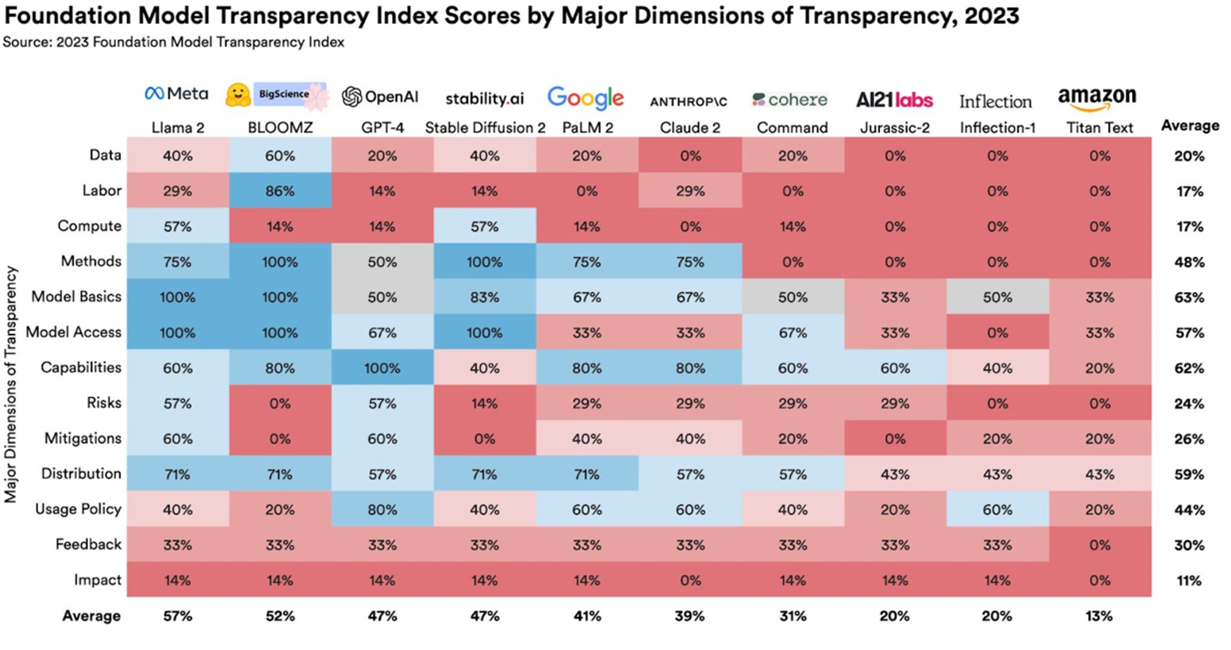
A further challenge with Large Language Models is the lack of transparency into the models. Researchers in the Stanford Institute for Human Centered AI created the ‘Foundation Model Transparency Index’ to examine the 10 most popular Foundation Models and how transparent they are across 100 different indicators of transparency. These indicators focused on how the technical teams build their models, including information about training data and the computational resources involved.
They also focused on the model itself, including its capabilities, trustworthiness, risks, and mitigation of those risks and how the models are being used downstream, including disclosure of company policies around model distribution, user data protection and model behaviour, and whether the company provides opportunities for feedback or redress by affected individuals. A summary of the findings is below which indicates that a lot more work is required to support Transparency of these models.
In the dynamic landscape of technological advancements, Generative AI has materialised as a generational leap, reminiscent of past transformations. The advent of ChatGPT, launched almost a year ago, has not only attracted an unprecedented user base, surpassing milestones faster than its digital counterparts, but has also created a broader societal conversation about Artificial Intelligence (AI), how and where it can be applied, and the challenges and risks associated with it.
The flexibility conferred by the extensive and diverse datasets on which Large Language Models are trained enables them to tackle a myriad of tasks across a diverse range of industries. As we navigate the transformative landscape of Generative AI, the past 12 months have illuminated the potential and challenges associated with this technology. While celebrating its milestones and accomplishments, a critical reflection on the ethical implications, transparency, and the essential role of human oversight becomes imperative to harness the true potential of Generative AI responsibly*.
* Note: The concluding paragraph is courtesy of ChatGPT.
Boost your digital skills
Are you looking to strengthen your expertise in digital and innovation? Explore IOB’s full portfolio of digital and innovation programmes to develop specialist knowledge and skills that will equip you to succeed in the ongoing transformation in financial services.



